Abstract.
Despite remarkable advancements in video depth estimation, existing methods exhibit inherent limitations in achieving geometric fidelity through the affine-invariant predictions, limiting their applicability in reconstruction and other metrically grounded downstream tasks.
We propose GeometryCrafter, a novel framework that recovers high-fidelity point map sequences with temporal coherence from open-world videos, enabling accurate 3D/4D reconstruction, camera parameter estimation, and other depth-based applications.
At the core of our approach lies a point map Variational Autoencoder (VAE) that learns a latent space agnostic to video latent distributions for effective point map encoding and decoding.
Leveraging the VAE, we train a video diffusion model to model the distribution of point map sequences conditioned on the input videos.
Extensive evaluations on diverse datasets demonstrate that GeometryCrafter achieves state-of-the-art 3D accuracy, temporal consistency, and generalization capability.
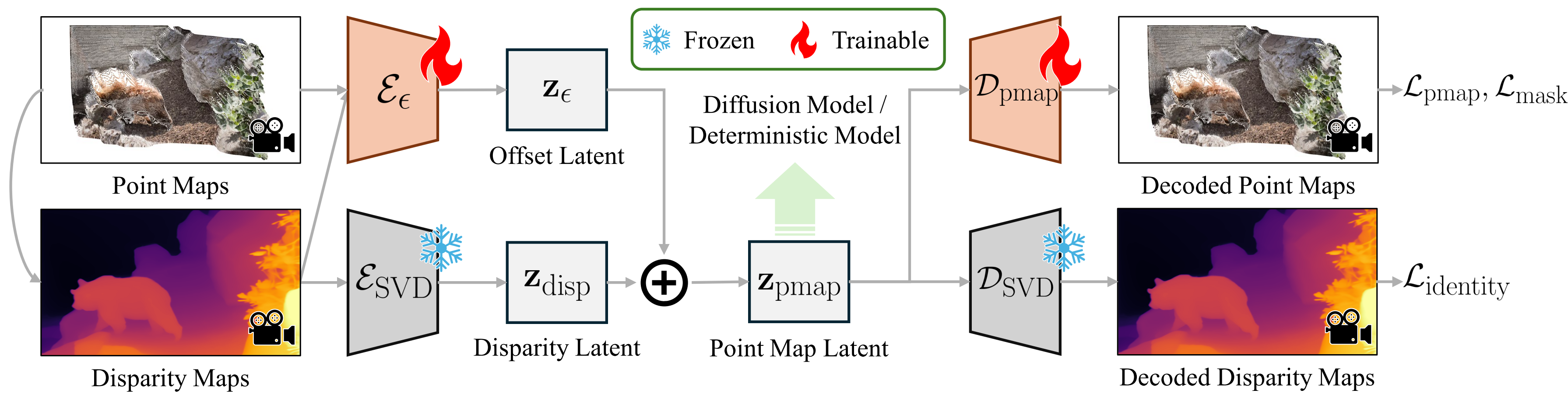
Point map VAE.
The point map VAE encodes and decodes point maps with unbounded values, alleviating the inaccurate prediction in distant regions.
We adopt a dual-encoder design: the native encoder E_SVD inherited from SVD captures normalized disparity maps, while a residual encoder E_eps embeds remaining information as an offset.
It preserves the original latent space by regulating the latents via the original decoder D_SVD, enabling the utilization of pretrained diffusion priors.
A point map decoder D_pmap recovers the final point maps from the latent codes.
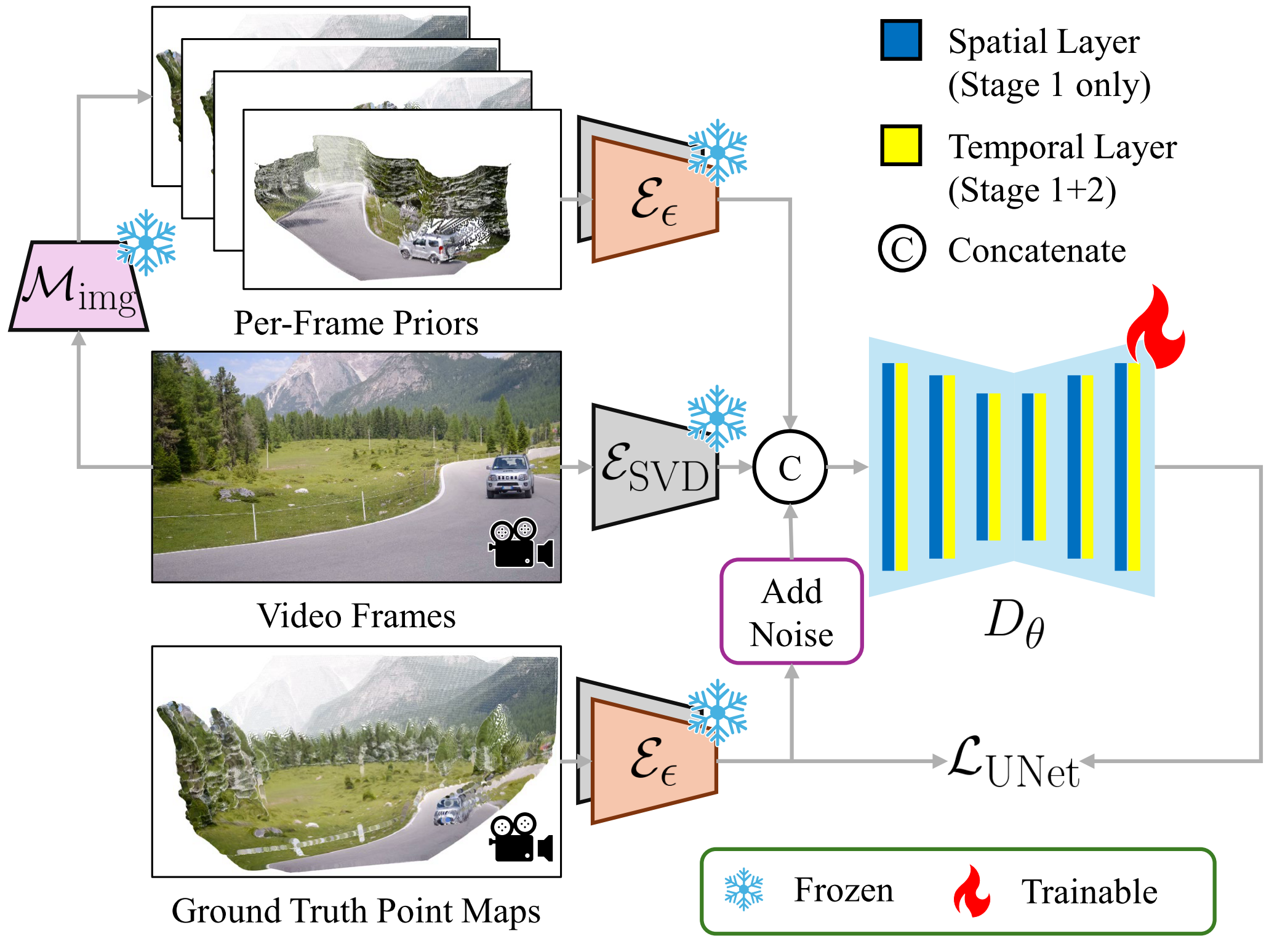
Per-Frame geometry prior diffusion UNet.
We jointly condition the diffusion model on video latents and per-frame geometry priors from an image MGE model M_img.
The geometry is encoded into latent space via our point map VAE, while the video latents are obtained from the native VAE.